1. はじめに
関係データマイニングとは、複数の関係表で表現されたデータから隠された知識やパターンを発見するプロセスです。この分野はMRDM(Multi-Relational Data Mining) といい、帰納論理プログラミング(Inductive Logic Programming: ILP)で扱われてきました。ILP は述語論理を用いた記述により、豊かな表現力と高い可読性を持っています。
複数の関係表をそのままマイニングすることのできるMRDM手法は汎用の関係DBに適しています。しかし、ILPの分野で扱われてきたMRDM手法は、関係DBとは分離した実装がされてきました。述語論理で記述されたデータを計算機の主記憶上で使用してきたことも問題の1つです。
そこで、汎用の関係DB中に格納された複数の関係表を対象としたMRDMシステムの実装を目標とします。
ボトムアップに基本パターンを抽出し、それの組み合わせに限定して高速にパターンを枚挙する手法にMAPIXがあります。本研究では、RDBMS(関係DB管理システム)上のデータをマイニングできるようにMAPIXの実装方法を与えます。
2. 関係データマイニング
簡単な例を用いてMRDMにおけるパターンマイニングについて説明します。列車に関する以下のようなデータベースを考えます。
このデータベースには、列車を登録する関係表trainや、列車がどの貨車を持っているかを表す関係表hascar、貨車に積まれている荷物の特徴を表す関係表triangle、circleなどの複数の関係表があるとします。
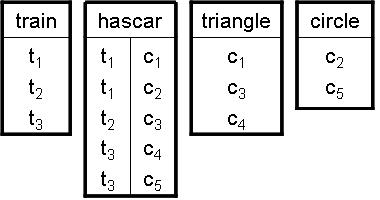
関係データマイニングでは、このような複数の関係表から、keyテーブルと呼ばれる対象とする関係表を選択し、その中のタプルに現れるパターンの中で、与えられた頻度の閾値を満たすパターンを発見していきます。そのようなパターンは、頻出パターンと呼ばれます。
例えば、この列車のデータベースに関して、「列車Aは三角形の荷物を積んだ貨車Bを持つ」というパターンを考えるとすると、このパターンは次の式のように表現されます。
| train(A)←hascar(A,B)∧triangle(B). |
述語には各引数が入力、または出力かを表すモードが定められていて、おのおの+,-で表現されます。例えば、列車の関係データベースでは、各述語モードはhascar(+,-),triangle(+),circle(+)です。
MAPIXでは、このモードに注目して、述語を二つのクラスに分けます。第一のクラスは全ての引数が入力モードとなっている判定述語(triangle、circle)です。第二のクラスは入力モードと出力モードをあわせ持つ経路述語(hascar)です。また、各述語で構成されたリテラルを判定リテラル,経路リテラルと呼びます。このとき、1つの判定リテラルといくつかの経路リテラルで構成され、引数が注目する対象から判定リテラルの引数まで経路リテラルにより鎖状につながっているリテラル集合を対象についての事実であると考えることができます。
このリテラル集合を性質と呼び、これは属性の拡張表現とみなすことができます。
以下にMAPIXアルゴリズムの流れを示します。
①.与えられたkeyテーブルからいくつかの事例を選択し、その事例の関連リテラル集合を生成する
②.選択した事例に関する関連リテラル集合から性質を抽出する
③.DB中の性質の頻度を計算し、頻出な性質とその組み合わせに限定して頻出パターンを枚挙する
事例の関連リテラル集合とは、事例と以下のような関連性をもつDB中のリテラルです。
・事例自身は関連リテラルである
・DB中のあるリテラルについてその全ての入力引数が関連リテラルの出力モードの引数の中に現れる場合、そのリテラルも関連リテラルである
つまり、入力引数の項から出力引数の項へと経由していき、目標の事例へとたどり着くことができる全てのリテラルの集合が関連リテラル集合です。例えば、列車のデータベースの事例train(t1)の関連リテラルは以下のものす。
| train(t1),hascar(t1,c1),hascar(t1,c2),triangle(c1),circle(c2) |
3. RDBMSへと結合したMRDM手法の提案
MAPIXアルゴリズムの操作をPrologプログラム側とRDBMS側とに分割することで実装をおこいます。これの基本手順は以下のとおりです。
RDBMS : RDBMS上のkeyテーブルから事例を選択し、関連リテラル集合を生成する
Prolog : 関連リテラル集合をProlog側で論理形式に変換し、性質を生成する
RDBMS : 事例が満たす性質を記録したトランザクションテーブルを生成する
RDBMS : トランザクションテーブル中の性質の全ての頻出な組み合わせを生成する
ここで、Prolog側の操作はMAPIXと同様の手法を用います。また、頻出なパターンを枚挙する手法はS.Sarawagiらによりで研究されています。
基本手順では、関連リテラル集合を生成するとき、以下のような問題点があります。
①.関係表中の入力モードが1つに限定されている
②.関係表の数が多い場合、結合の回数が増大し、計算量が大きくなってしまう
③.テーブルが保持できる最大の列数を越えてしまう場合、すべての関連リテラルを集められない
④.テーブル中に同じリテラルの情報がいくつも格納されてしまう
⑤.一度、集めたリテラル中の項がもう一度現れた場合、同じように集めてしまう
そのため、以下のアイディアを導入するすることにより基本手順を改善します。
①.関連リテラルのテーブルに関係表の中のリテラルの各項が現れているかどうかの出現検査を行う
②.同じ情報を持つ関係表を1つにまとめる
③.関係表ごとに関連リテラルをテーブルに格納する
④.既に集められた関連リテラル中の項の中で処理済みの項と未処理の項を判別し、未処理のものだけから探索していく
4. 実験と実装
PrologとDBを操作するためのOpen DataBase Connectivityインタフェースを用いて実装をしました。
2つのデータ集合を用いて、提案手法と元のMAPIXの実行時間を比較しました。
1つ目は、英文の文法構造に関するものです。このデータ集合を用いて、トランザクションテーブルを生成するまでの実行時間を計測しました。選択する事例数と5回の実行の処理時間の平均を計測したところ、元のMAPIXと比較して短い処理時間を得ました。
2つ目はMutagenesisというILP問題において利用されてきたデータ集合です。このデータ集合は、突然変異性を持つ有機物質を含む化学物質の構造データであり、複数の入力モードを持つ関係表が含まれています。全事例の230個を用いて、先ほどと同様の実験をして動作を確認しました。 また、実行時間は、MAPIXと比較して、提案手法の方が数倍の時間がかかることになりましたが、これは事例が少ないためオーバヘッドがかかっていると考えられます。
5. まとめ
本研究では、MRDM手法であるMAPIXを汎用の関係DBに接続することによりマイニングをおこなう実装手法を提案しました。この提案手法により、関係データマイニングを大規模なDBへと適用するための方向性を示すことができたと思われます。 今後の課題としては、\MAPIX{}の機能の一部について実装できていない部分を実装する必要があります。また、マイニングされたパターンの可視化などのインタフェース機能などのシステム全体の課題や、大規模なDBへの応用などが課題として残っています。