1. はじめに
データマイニングとは、 蓄積された大量のデータから価値のある知識を取り出すプロセスのことです。 データマイニングの手法の一つとして、 事例から性質を抽出してこれをマイニングに用いる、 MAPIX (Mining Algorithm by Property Item eXtraction) アルゴリズムが開発されました。 しかし、MAPIXでは ビューを扱っていない、 あるいは元々あるデータにはユーザの理解に及ばない部分があるなど、 物理レベルデータとユーザレベルデータが一致しないとい う問題点がありました。 そこで、本研究では物理レベルとユーザレベルを明確に分 け、ユーザレベルでマイニングを行う手法を提案します。
2. MAPIX
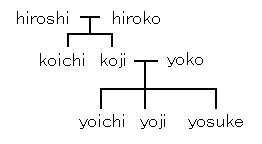
簡単な例として上図の家族関係について考えます。 これは、親子の関係を表すparentと性別を 表すmale, femaleという述語で構成されています。 上図においてhiroshiに着目したとき、 hiroshiにはkojiという息子がいること、 hiroshiにはyojiという男の孫がいることは 次のように表されます.
parent(hiroshi, koji) ∧ male(koji).
parent(hiroshi, koji) ∧ parent(koji, yoji) ∧ male(yoji).
このように対象hiroshiがもつ事実を表す述語の組を、 hiroshiの性質と考えることができます。 MAPIXでは、性質を取り出すために飽和節を生成します。 これは、注目した事例に関連するデータを集めて来たものであり、 全ての性質が含まれています。 MAPIXの概要を次に示します。
1. 与えられた事例の集合からいくつかの事例を選択し、その飽和節を生成する。
2. 飽和節の前提部のリテラルの集合から、事例に関する性質を取り出す。
3. 事例の性質を使って、興味深いパターンを枚挙する。
3. 提案手法
本研究では、まずビュー(ルールで表現される仮想的な表)を扱えるようにMAPIXを拡張します。 これは、MAPIXの飽和節を生成するアルゴリズムを改良することにより実現できます。 この拡張により、今までは得られなかったパターンが得られるようになります。
次に、ユーザレベルデータベース(ユーザにとって必要なデータ) だけを利用してマイニングできるように、飽和節生成アルゴリズムを改良します。 これは、ユーザが使いたいデータを宣言することにより実現できます。 この拡張により、得られるパターンの可読性が増し、計算時間を短縮することができます。
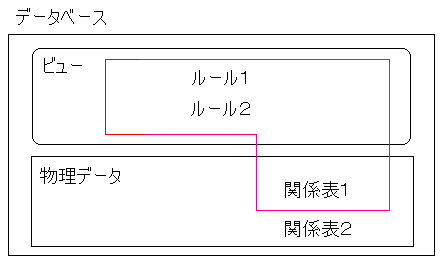
ユーザレベルデータベースを図で表すと、以下のようになります。 赤線で囲まれた部分がユーザレベルデータベースとなります。
4. 実験結果
まず、既存手法の飽和節生成アルゴリズムと、提案手法のビューを扱える飽和節生成アルゴリズムの実行時間を比較しました。 実験には、家族関係のデータベースと物質の突然変異性に関するデータベースを使用しました。実験結果を次に示します。
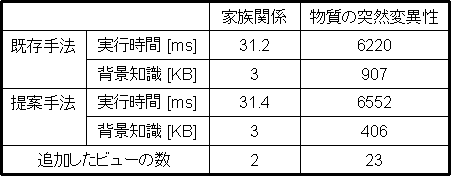
実行時間の差は1秒以下という結果になりました。また、ビューを使うことにより、背景知識のデータ量を削減できたことも確認できました。
次に、データベース全体からマイニングしたときと、ユーザレベルデータベースからマイニングしたときのMAPIXの実行時間を比較しました。 実験には物質の突然変異性に関するデータベースを使用しました。 実験結果のグラフを次に示します。
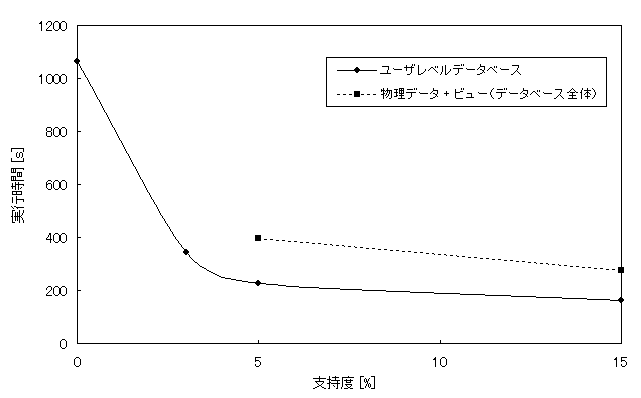
グラフの横軸は閾値、縦軸は実行時間です。一般に、閾値が低くなるほど実行時間が長くなる傾向があります。 実験に用いた物質の突然変異性のような 巨大なデータベースからマイニングした場合、既存手法では閾値が低いと現実的な時間では結果を得ることができませんでした。 それに対し、提案手法では閾値が低い場合でも結果を得ることができました。 ユーザレベルデータベースからマイニングすることにより、実行時間が短縮されたことを確認できました。